

Введение
Освоить сильную стратегию поиска элементов - обязательный навык в UI-автоматизации на Selenium / Playwright / Appium. На практике чаще всего используют CSS и XPath: они дают больше гибкости и контроля, чем более простые варианты вроде id, name, class name, tagName, linkText и partialLinkText. С большинством этих стратегий инженеры по автоматизации обычно уже знакомы.
У разных инструментов есть свои «удобные» способы поиска элементов. В Selenium 4 появились Relative locators (например, near, above, below, toLeftOf, toRightOf). В Playwright есть собственные подходы и рекомендуемые типы локаторов (например, по роли, по тексту, по test id), которые часто дают более стабильные тесты. Но при этом CSS-селекторы остаются универсальным и очень полезным инструментом, который регулярно нужен и в Selenium, и в Playwright, и в Appium (в веб-контексте).
Цель этого поста - помочь инженерам по автоматизации, особенно новичкам, понять, почему важно уметь выбирать хорошие локаторы, и дать понятный путь к освоению CSS-стратегии.
Сначала мы сравним CSS и XPath в контексте Selenium и Playwright. Затем разберём практическое использование CSS и обсудим несколько типичных «болевых точек». В середине статьи будут перечислены основные варианты CSS-селекторов: синтаксис, HTML-фрагменты и примеры. В конце мы рассмотрим инструменты для конвертации XPath в CSS, генераторы CSS-селекторов, инструменты валидации, а также игру для практики CSS. В завершение добавлены шпаргалка (cheatsheet) и глоссарий.
При подготовке этого поста мы использовали широкий набор онлайн-ресурсов, а также опыт из наших обучающих программ и проектов по автоматизации.
Удачной автоматизации тестирования!
Что такое CSS?
Cascading Style Sheets (CSS, «каскадные таблицы стилей») - это простой язык оформления, который помогает делать веб-страницы визуально аккуратными и удобными.
CSS отвечает за внешний вид страницы. С его помощью можно управлять цветом текста, стилем шрифтов, расстоянием между абзацами, шириной и расположением колонок, фоном (цветом или изображениями) и многими другими визуальными эффектами.
CSS или XPath
CSS и XPath - самые популярные, широко используемые и мощные стратегии локаторов в UI-автоматизации (в том числе в Selenium и Playwright). CSS часто выбирают по следующим причинам (так обычно говорят сторонники CSS):
- CSS более читабельный (проще).
- CSS традиционно считается немного быстрее – хотя современные замеры показывают, что примерно одинаково.
Сторонники XPath, в свою очередь, выделяют его способность перемещаться по странице там, где CSS ограничен: XPath может идти «вверх» и «вниз» по структуре документа, а CSS в основном двигается «вниз» по DOM.
Впрочем, эти утверждения могут быть уже неактуальны. Некоторые исследования показывают, что заметной разницы в скорости выполнения CSS и XPath нет.
Ниже приведена цитата из документации Mozilla Developer Network:
Note: There are no selectors or combinators to select parent items, siblings of parents, or children of parent siblings.
Освоение и XPath, и CSS - хорошая инвестиция для инженера по автоматизации, который строит карьеру вокруг Selenium / Playwright.
Для одного проекта обычно лучше придерживаться одной основной стратегии локаторов - так проще поддерживать и развивать тесты.
Некоторые эксперты советуют гибридный подход: сначала использовать id и name, затем переходить на CSS, а XPath применять только тогда, когда он действительно нужен.
Хорошие локаторы
В этом разделе мы разберём, какими свойствами должен обладать хороший локатор. Наша цель - выбрать максимально удачный CSS-селектор из возможных вариантов.
Хороший локатор должен быть:
- описательным (Descriptive),
- устойчивым (Resilient),
- коротким (Shorter in length),
- уникальным (Unique), если вам нужно найти один конкретный элемент.
Если вы хотите обратиться к одному элементу, CSS-локатор должен подходить ровно к одному кандидату, то есть быть уникальным. Когда селектор описательный, читать и понимать тест проще. Также важно, чтобы элемент стабильно находился по этому локатору при повторных запусках тестов в следующих релизах. Поэтому селектор стоит выбирать так, чтобы он оставался валидным даже после изменений DOM.
Когда вы хорошо знаете CSS, у вас почти всегда будет несколько вариантов селектора. Обычно стоит выбирать более короткий вариант, чтобы тесты были читабельнее и проще в поддержке.
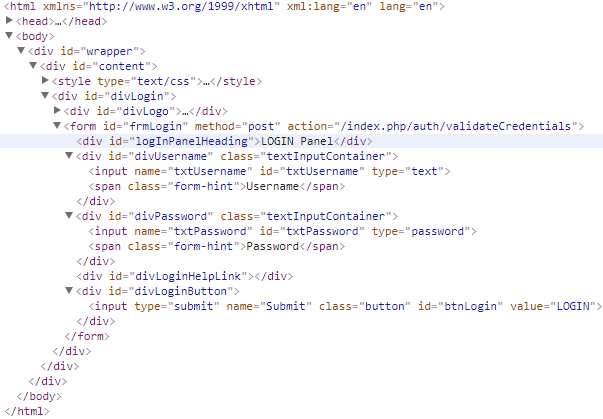
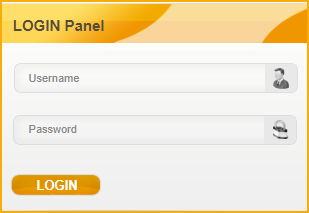
Пример HTML
Дальше мы будем использовать следующий HTML - простую форму логина - чтобы в большинстве случаев объяснять синтаксис CSS.
Термины
Давайте познакомимся с наиболее часто используемыми терминами в синтаксисе CSS.
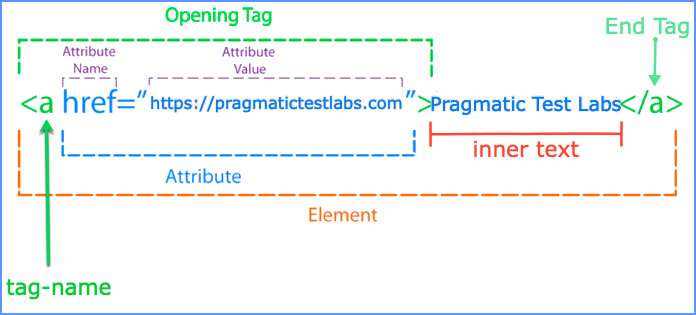
Основные термины с картинки:
- tag-name (имя тега) — «тип» элемента. Например, a, div, input.
- Opening Tag (открывающий тег) — начало элемента, например: <a ...>.
- End Tag (закрывающий тег) — конец элемента, например: </a>.
- Element (элемент) — вся конструкция целиком: открывающий тег + содержимое (если есть) + закрывающий тег.
- Attribute (атрибут) — дополнительное свойство элемента внутри открывающего тега, например href="...".
- Attribute Name (имя атрибута) — название свойства, например href, id, class, name.
- Attribute Value (значение атрибута) — значение этого свойства, обычно в кавычках, например "https://...", "txtUsername".
- inner text (внутренний текст) — текст между > и </...>, который виден пользователю, например Pragmatic Test Labs.
Поиск элементов по известному значению атрибута
Следующий синтаксис можно использовать, чтобы найти элементы по известному значению атрибута.
Синтаксис:
[attribute-name='attribute-value’]

Примеры:
Посмотрим, как найти поле username с помощью этого синтаксиса:
[id=’txtUsername’]
[name=’txtUsername’]
[type=’text’]
Третий вариант не стоит использовать, если вам нужно выбрать элемент уникально, даже несмотря на то, что синтаксис валидный. Элементов с type='text' обычно много, и такой селектор не будет уникальным. Тогда поведение зависит от инструмента и настроек: иногда будет выбран первый подходящий элемент, а иногда тест может упасть из-за того, что локатор не уникален.
В реальной жизни это похоже на ситуацию, когда мы пытаемся найти человека в группе по имени. Если имя слишком распространённое, например Mohammed в мусульманском сообществе, однозначно найти человека по одному имени не получится - нужно использовать дополнительные признаки.
Если же вам как раз нужны все элементы с общим атрибутом, обычно используют метод, который возвращает список совпадений, и затем проходят по этому списку.
Поиск элементов по известному имени тега и значению атрибута
Следующий вариант можно использовать, чтобы находить элементы по известному имени тега и значению атрибута.
Синтаксис:
tag-name[attribute-name='attribute-value']

Примеры:
input[id=’txtUsername’]
input[name=’txtUsername’]
input[type=’text’]
Примечание:
- Значения атрибутов нужно заключать в одинарные или двойные кавычки.
- Если значение содержит кавычки, используйте escape-символ - обратный слэш \.
Поиск элементов по ID
В CSS символ # используется для поиска элементов по значению атрибута id.
Синтаксис:
tag-name#valueOfId
#valueOfId

Примеры:
input#txtUsername
#txtUsername
Поиск элементов по class
Элемент можно найти по одному из классов (значений) в атрибуте class.
Синтаксис:
tag-name.className
.className

Примеры:
input.button
.button
Поиск элементов по нескольким классам
Несколько классов можно указывать через точку, как в следующем синтаксисе.
Синтаксис:
tag-name.className1.className2….classNameN
.className1.className2….classNameN

Примеры:
div.box.searchForm.toggleForm
box.searchForm
Не обязательно указывать все классы. Если вы выбираете локатор по классам, лучше использовать минимально необходимое количество, чтобы селектор оставался коротким и при этом выбирал элемент уникально.
Поиск элементов по class и атрибуту
Синтаксис:
tag-name.className[attribute-name=’attribute-value’]
.className[attribute-name=’attribute-value’]

Примеры:
input.button[name=’Submit’]
.button[name=’Submit’]
Поиск элементов по нескольким атрибутам
Иногда элемент нельзя однозначно найти по одному атрибуту. В реальной жизни похожая ситуация: человека сложно идентифицировать только по имени или только по фамилии - обычно нужен набор признаков, чтобы не перепутать.
Синтаксис:
tag-name[a-name1=’a-value1’][a-name2=’a-value2’]
..[a-nameN=’a-valueN’]
[a-name1=’a-value1’][a-name2=’a-value2’] ..[a-nameN=’a-valueN’]

Примеры:
input[id=’txtUsername’][name=’txtUsername’]
[id=’txtUsername’][name=’txtUsername’]
Использовать несколько атрибутов не обязательно, если одного атрибута достаточно, чтобы уникально выбрать целевой элемент. Как правило, чтобы сделать селектор уникальным, обычно хватает одного-двух атрибутов.
Поиск дочерних элементов по имени тега
Можно находить прямых детей относительно известного родительского элемента с помощью символа >. У элемента может быть ноль, один или много дочерних элементов.
Синтаксис:
CSS-of-Parent > element
CSS-of-Parent > *

Примеры:
div#divUsername > input
div#divUsername > *
В первом примере выбирается элемент input. Если использовать универсальный селектор *, будут выбраны все дочерние элементы (например, input и span).
Поиск элементов-потомков по имени тега
Если между селекторами поставить пробел, будут выбраны все элементы внутри контекстного элемента (то есть не только прямые дети, но и элементы глубже по вложенности). Если использовать *, будут выбраны вообще все элементы внутри контекстного элемента.
Синтаксис:
CSS-of-Context-Element <пробел> tag-name
CSS-of-Context-Element <пробел> *
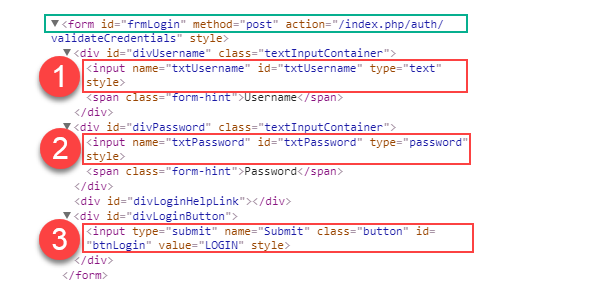
Примеры:
form input
form *
В первом примере будут выбраны три (3) элемента input внутри form. Во втором примере будут выбраны все элементы внутри form.
Что делать, если селектор подходит нескольким элементам
Иногда один и тот же CSS-селектор соответствует сразу нескольким элементам. Дальнейшее поведение зависит от инструмента и настроек: в одних случаях можно получить коллекцию всех совпадений, в других - «молча» берётся первое совпадение, а в строгих режимах тест может упасть из-за неуникального локатора.
Пример (Selenium):
WebElement txtUsername = webDriver.findElement(By.cssSelector("form input"));
Пример (Playwright):
const txtUsername = page.locator("form input").first();
Важные заметки про методы, которые возвращают один элемент и коллекцию
Если элемент может отсутствовать, не стоит использовать метод, который ожидает ровно один элемент: в зависимости от инструмента и настроек вы получите ошибку/таймаут. В таких сценариях безопаснее использовать метод, который возвращает коллекцию совпадений, и уже по длине коллекции проверять, что элементов 0 (или 1, если нужна уникальность).
Selenium
- Метод findElement предназначен для ситуации, когда вы ожидаете один элемент. Если элемент не найден, обычно будет ошибка (часто после ожидания до таймаута, если у вас включены ожидания/ретраи).
- Если селектор подходит нескольким элементам, findElement вернёт первый найденный элемент. Он не будет «ждать другой» элемент с тем же селектором.
- Метод findElements возвращает все совпадения (список). Если совпадений нет - вернёт пустой список, и это удобно для проверок «элемент отсутствует».
Пример (Selenium):
List<WebElement> inputElements = webDriver.findElements(By.cssSelector("form input"));
Playwright
- page.locator("...") создаёт локатор, который потенциально может соответствовать нескольким элементам.
- Если вы хотите работать с одним элементом, обычно явно уточняют намерение: берут first()/nth() или используют «строгий» режим (strict), где действие/ожидание падает, если совпадений больше одного.
- Для сценариев, где элемент может отсутствовать, обычно используют подсчёт совпадений и проверяют, что их 0 (или нужное число).
Пример (Playwright):
const inputElements = page.locator("form input");
Поиск N-го дочернего элемента по имени тега
Этот синтаксис можно использовать, чтобы выбрать элемент из списка «соседних» элементов (siblings) по его позиции среди однотипных элементов.
Синтаксис:
CSS-of-Context-Element <пробел> tag-name:nth-of-type(N)
CSS-of-Context-Element <пробел> *:nth-of-type(N)
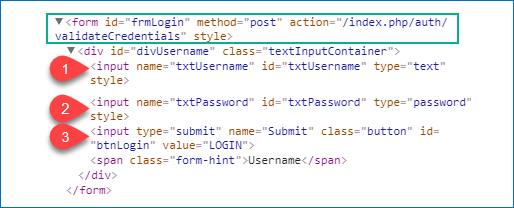
Примеры:
form input:nth-of-type(1) - выбирает первый элемент input
form input:nth-of-type(3) - выбирает третий элемент input
Также:
- :first-of-type можно использовать, чтобы выбрать первого «соседа» среди однотипных элементов;
- :last-of-type - чтобы выбрать последнего;
- :only-of-type - чтобы выбрать элемент, у которого нет «соседей» с тем же именем тега.
Поиск первого соседа (first-child)
Следующий синтаксис можно использовать, чтобы выбрать первый элемент из группы соседних элементов.
Синтаксис:
CSS-of-Context-Element <пробел> element:first-child
CSS-of-Context-Element > element:first-child
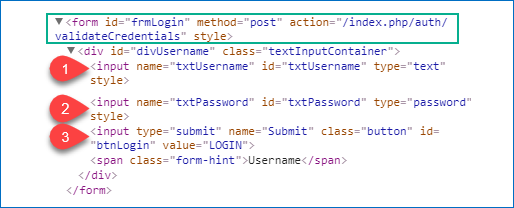
Примеры:
В следующих примерах мы выбираем поле username среди трёх подходящих элементов:
form > div > input:first-child
form input:first-child
Поиск последнего соседа (last-child)
Можно использовать :last-child, чтобы выбрать последний элемент из группы соседних элементов.
Синтаксис:
CSS-of-Parent-Element <пробел> element:last-child
CSS-of-Parent-Element > element:last-child
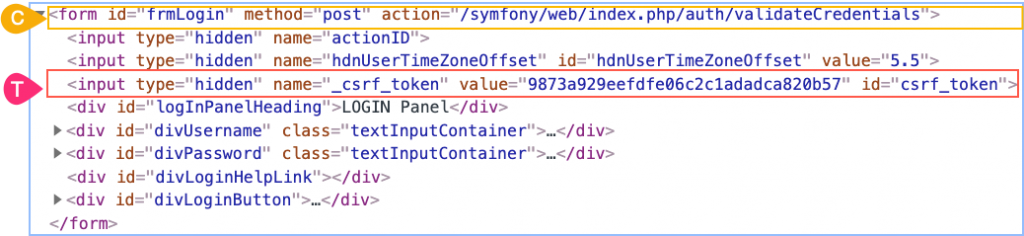
Примеры:
form#frmLogin > input:last-child
form#frmLogin > div:last-child
form#frmLogin > *:last-child
В первом примере будет выбран третий input (как на рисунке). Во втором и третьем примерах будет выбран последний div.
Поиск соседей по позиции
Можно использовать :nth-child(n), чтобы выбрать элемент по позиции от начала списка соседей, и :nth-last-child(n), чтобы выбрать элемент по позиции от конца.
Синтаксис:
CSS-of-the-Siblings:nth-child(n)
CSS-of-the-Siblings:nth-last-child(n)
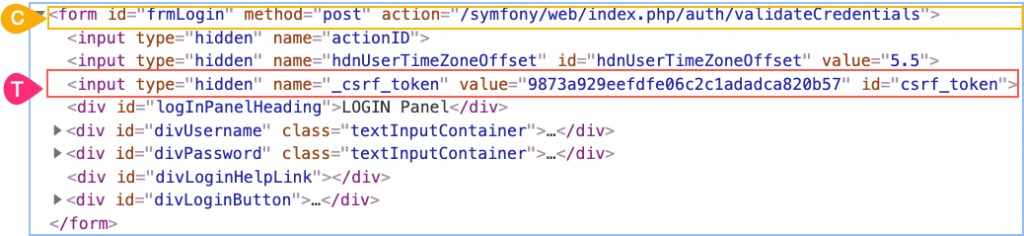
Примеры:
form#frmLogin > input:nth-child(3)
form#frmLogin > *:nth-last-child (6)
В первом и втором примерах будет выбран третий input (как показано на рисунке).
Также:
- :only-child можно использовать, чтобы выбрать элемент без соседей;
- :empty - чтобы выбрать элементы без дочерних элементов;
- :only-of-type - чтобы выбрать элемент, у которого нет соседей с тем же именем тега.
Поиск элементов по префиксу значения атрибута
Это полезно, когда значение атрибута динамическое, но всегда начинается с фиксированной строки.
Синтаксис:
tag-name[attribute-name^=’fixed-prefix-of-value’]
[attribute-name^=’fixed-prefix-of-value’]

Примеры:
a[href^=’https://www.amazon.com/Magnasonic-‘]
[href^=’https://www.amazon.com/Magnasonic-‘]
Поиск элементов по суффиксу значения атрибута
Подходит, когда вы знаете, что динамическое значение атрибута имеет фиксированное окончание (суффикс).
Синтаксис:
tag-name[attribute-name$=’fixed-suffix’]
[attribute-name$=’fixed-suffix’]

Примеры:
input[name$=’name’]
[name$=’name’]
Поиск элементов по подстроке в значении атрибута
Подходит, когда известна фиксированная часть (подстрока) внутри значения атрибута.
Синтаксис:
tag-name[attribute-name*=’fixed-substring-of-the-value’]

Примеры:
a[href*=’Magnasonic-Professional‘]
[href*=’Magnasonic-Professional‘]
Поиск элементов по одному слову в значении атрибута
Это полезно, когда значение атрибута состоит из нескольких слов, разделённых пробелами.
Синтаксис:
tag-name[attribute-name~=’a white space separated value’]

Пример:
span[style~=’display:’]
Примечание:
[attribute-name|=’value’] можно использовать для поиска элемента, у которого значение атрибута точно равно value, либо начинается с value, после чего сразу идёт дефис - (hyphen).
Поиск следующего соседа по известному имени тега
Следующий синтаксис используется, чтобы найти непосредственно следующий соседний элемент (immediate next sibling), который идёт сразу после контекстного элемента.
Синтаксис:
CSS-of-context-element + tag-name
CSS-of-context-element + *

Примеры:
[name=’actionID’] + input
[name=’actionID’] + div
[name=’actionID’] + *
В первом примере будет выбран второй input. Во втором примере ничего не будет выбрано (потому что сразу после контекстного элемента нет div). В третьем примере снова будет выбран второй input.
Поиск всех следующих соседей известного элемента
Следующий синтаксис используется, чтобы выбрать элементы, которые идут после контекстного элемента и имеют того же родителя. При этом потомки (вложенные элементы) не выбираются - речь именно о «соседях» на одном уровне.
Синтаксис:
CSS-of-context-element ~ tag-name
CSS-of-context-element ~ *
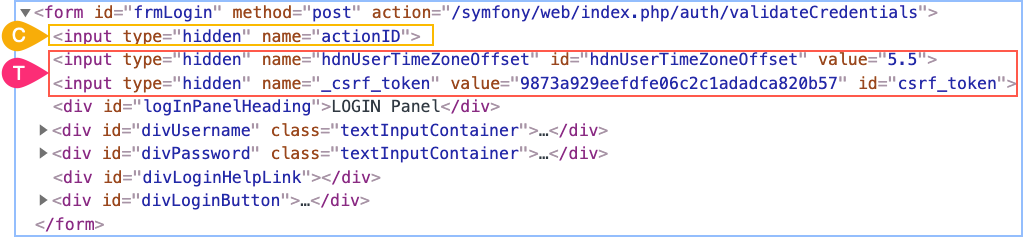
Примеры:
[name=’actionID’] ~ input
[name=’actionID’] ~ div
[name=’actionID’] ~ *
В первом примере будут выбраны два input, которые идут после контекстного элемента. Во втором примере будут выбраны пять div. В третьем примере будут выбраны все семь элементов, которые идут после контекстного элемента.
Поиск элемента по части видимого текста (inner text)
В стандартных CSS-селекторах нет надёжного способа искать элементы по тексту между открывающим и закрывающим тегом. Это одно из ограничений CSS.
Иногда можно встретить запись вроде:
tag-name:contains('part-of-the-text')
Но это не является универсальным стандартом CSS и может не поддерживаться в разных инструментах.
Если вам нужно искать элемент по innerText (видимому тексту внутри элемента), обычно используют XPath или текстовые локаторы, которые предоставляет конкретный инструмент (например, поиск по тексту в Playwright).

Синтаксис XPath:
//element-name[text()=’exact-innerText‘]
//element-name[contains(text(),’part-of-innerText‘]
Поиск по атрибутам без учёта регистра
Можно искать элементы, игнорируя регистр в значении атрибута, добавив символ i или I после значения.
Синтаксис:
tag-name[Attribute=’Value’ i]
[Attribute=’Value’ I]

Примеры:
[id=’txtusername‘ i ]
[id=’txtUSERNAME‘ I ]
input[id=’txtusername‘ i ]
Поиск элементов без конкретного значения атрибута
Это полезно, когда нужно убедиться, что у элемента нет определённого значения атрибута. Псевдокласс :not() позволяет выбрать элементы, которые не соответствуют условию внутри скобок.
Синтаксис:
css-of-context-node:not([attribute2='value2'])
Пример:
Допустим, вы хотите выбрать все input, которые не скрыты:
input:not([type=’hidden‘])
Поиск выбранных и отмеченных элементов (selected / checked)
Следующий синтаксис можно использовать для поиска выбранных (или невыбранных) элементов: отмеченных radio/checkbox и выбранных option.
Синтаксис:
css-of-the-element:checked
css-of-the-element:not(:checked)

Примеры:
Допустим, вы хотите выбрать все выбранные и не выбранные options:
option:checked
option:not(:checked)
Поиск элементов по нескольким CSS-селекторам
Можно объединить два или больше CSS-селектора, разделив их запятой. Тогда будут выбраны элементы, которые подходят хотя бы под один из селекторов.
Синтаксис:
CSS-Selector1, CSS-Selector2, ... , CSS-SelectorN
Пример:
Допустим, нужно выбрать все input с типом text, password и submit:
[type=’text‘], [type=’password‘], [type=’submit‘]
Заключение
CSS-селекторы - один из базовых инструментов для поиска элементов в UI-автоматизации. Они обычно читаются проще, чем XPath, хорошо подходят для устойчивых локаторов на основе id, классов и других атрибутов, и отлично работают, когда структура страницы предсказуема.
При выборе селектора ориентируйтесь на те же принципы, что и для любых локаторов: он должен быть уникальным, коротким, понятным и устойчивым к изменениям DOM. Если вариантов несколько - выбирайте самый простой, который надёжно идентифицирует элемент и не зависит от лишних уровней вложенности.
Также важно помнить про ограничения CSS: например, стандартные CSS-селекторы не дают универсального способа искать элементы по видимому тексту. В таких случаях разумно использовать XPath или текстовые локаторы, которые предоставляет конкретный инструмент (например, Playwright).
Итог простой: вы получите максимальную гибкость, если уверенно владеете и CSS, и XPath, но внутри одного проекта лучше придерживаться единых правил и договорённостей по локаторам - это сильно упрощает поддержку тестов.
У нас есть такая же статья про XPath.
Спасибо! :)
У нас есть такая же статья про XPath.
Спасибо! :)